คุณเคยฟังเสียงอัตโนมัติแล้วสงสัยไหมว่าทำไมมันถึงไม่ฟังดูเหมือนหุ่นยนต์ที่ไร้อารมณ์และพูดจาแข็งทื่ออีกต่อไป? ความลับเบื้องหลังเสียงพูดที่สมจริงและเหมือนมนุษย์นี้ก็คือ... TTS ระบบประสาท. ไม่ว่าคุณจะใช้แอปนำทาง ฟังหนังสือเสียง หรือใช้โปรแกรมแปลเสียง AI สำหรับการประชุมระดับโลก เทคโนโลยีขั้นสูงนี้คือหัวใจสำคัญที่ขับเคลื่อนประสบการณ์เหล่านั้น.
ในคู่มือฉบับนี้ เราจะสำรวจว่าเทคโนโลยีนี้คืออะไร ทำงานอย่างไรในเชิงลึก และแพลตฟอร์มสมัยใหม่ใช้ประโยชน์จากเทคโนโลยีนี้อย่างไรเพื่อทำลายอุปสรรคทางภาษาได้ทันที.
Neural TTS คืออะไรกันแน่?
โดยพื้นฐานแล้ว, TTS ระบบประสาท เป็นวิธีการ AI ขั้นสูงที่แปลงข้อความที่เขียนให้เป็นเสียงพูดที่ฟังดูเป็นธรรมชาติ.
แตกต่างจากระบบแปลงข้อความเป็นเสียงแบบดั้งเดิม ซึ่งเพียงแค่ต่อชิ้นส่วนเสียงที่บันทึกไว้ล่วงหน้าเข้าด้วยกันด้วยน้ำเสียงที่ราบเรียบและไร้ชีวิตชีวา ระบบสมัยใหม่เรียนรู้โดยตรงจากเสียงพูดของมนุษย์จริงหลายพันชั่วโมง โดยใช้การเรียนรู้เชิงลึกและโครงข่ายประสาทเทียม AI แปลงข้อความเป็นเสียงจึงเข้าใจความละเอียดอ่อนของภาษาของมนุษย์ รวมถึงจังหวะ ระดับเสียง และบริบททางอารมณ์.
ระบบ Neural TTS ทำงานอย่างไร?
เพื่อให้เข้าใจว่าการสร้างเสียงพูดนั้นมีความสมจริงได้อย่างไร เราจำเป็นต้องพิจารณาสามขั้นตอนหลักที่ระบบดำเนินการทุกครั้งที่พูด.
1. การวิเคราะห์ข้อความ
ขั้นแรก ระบบจะอ่านข้อมูลที่ป้อนเข้ามาเพื่อหาคำตอบ ยังไง เพื่อสื่อความหมาย ไม่ใช่แค่เพียงคำศัพท์เท่านั้น มันใช้การประมวลผลภาษาธรรมชาติ (NLP) ในการปรับตัวเลขให้เป็นมาตรฐาน ขยายคำย่อ และแก้ไขการออกเสียงที่ซับซ้อนตามบริบท ตัวอย่างเช่น มันจะพิจารณาว่าควรออกเสียงคำว่า “read” เป็น “reed” (ปัจจุบันกาล) หรือ “red” (อดีตกาล) ขึ้นอยู่กับประโยคโดยรอบ.
2. การสร้างแบบจำลองเสียง
ขั้นตอนต่อไป โมเดลจะแปลงข้อความที่ประมวลผลแล้วให้เป็นเมลสเปกโตรแกรม คุณสามารถนึกภาพว่านี่คือแผนที่ที่มีรายละเอียดสูงและกระชับของระดับเสียง โทนเสียง และจังหวะ ในขั้นตอนนี้เองที่ลักษณะที่เป็นธรรมชาติและเหมือนมนุษย์ของเสียงพูดถูกสร้างขึ้นมา.
3. เครื่องแปลงเสียง (Vocoder)
สุดท้าย ระบบจะแปลงแผนที่เสียงนั้นให้เป็นรูปคลื่นเสียงทางกายภาพ เครื่องแปลงเสียงขั้นสูง เช่น เครื่องแปลงเสียงที่ได้รับการกล่าวถึงอย่างกว้างขวาง ไฮไฟ-แกน, มีศักยภาพสูงในการสร้างผลลัพธ์ที่แทบแยกไม่ออกจากการบันทึกของมนุษย์จริง.
สถาปัตยกรรมเบื้องหลังการสังเคราะห์เสียงพูดสมัยใหม่
นักวิจัยได้พัฒนาแนวทางการเรียนรู้เชิงลึกหลายวิธีเพื่อขับเคลื่อนระบบเหล่านี้ ต่อไปนี้คือตารางเปรียบเทียบโดยสรุปเกี่ยวกับสถาปัตยกรรมหลักๆ:
| สถาปัตยกรรม | วิธีการสร้างเสียงพูด | ตัวอย่างโมเดล | จุดแข็งที่สำคัญ | ข้อจำกัดหลัก |
| อัตถารีเกรสซีฟ (AR) | ทีละก้าว | ทาโคตรอน 2, เวฟเน็ต | ความเป็นธรรมชาติสูง | ช้า ไม่ใช่ "เรียลไทม์" อย่างแท้จริง“ |
| แบบจำลองไม่ถดถอยอัตโนมัติ (NAR) | ลำดับเต็มรูปแบบแบบขนาน | ฟาสต์สปีช, ฟาสต์สปีช 2 | เร็วขึ้นสูงสุดถึง 270 เท่า | แสดงออกน้อยลงเล็กน้อย |
| แบบครบวงจร (E2E) | ข้อความเข้า เสียงออก – เครือข่ายเดียว | VITS, NaturalSpeech | ข้อผิดพลาดน้อยลง ผลลัพธ์สะอาดขึ้น | การฝึกฝนมีความซับซ้อนมากขึ้น |
บทบาทของเทคโนโลยีแปลงข้อความเป็นเสียงขั้นสูงในการแปลแบบเรียลไทม์
พลังที่แท้จริงของการสร้างเสียงด้วย AI จะปรากฏชัดเมื่อผสานรวมกับเครื่องมือการสื่อสารแบบเรียลไทม์ ลองนึกภาพการเข้าร่วมการประชุมทางธุรกิจระดับโลกที่ผู้เข้าร่วมพูดภาษาต่างกัน แต่คุณได้ยินทุกอย่างในภาษาแม่ของคุณได้ทันที.
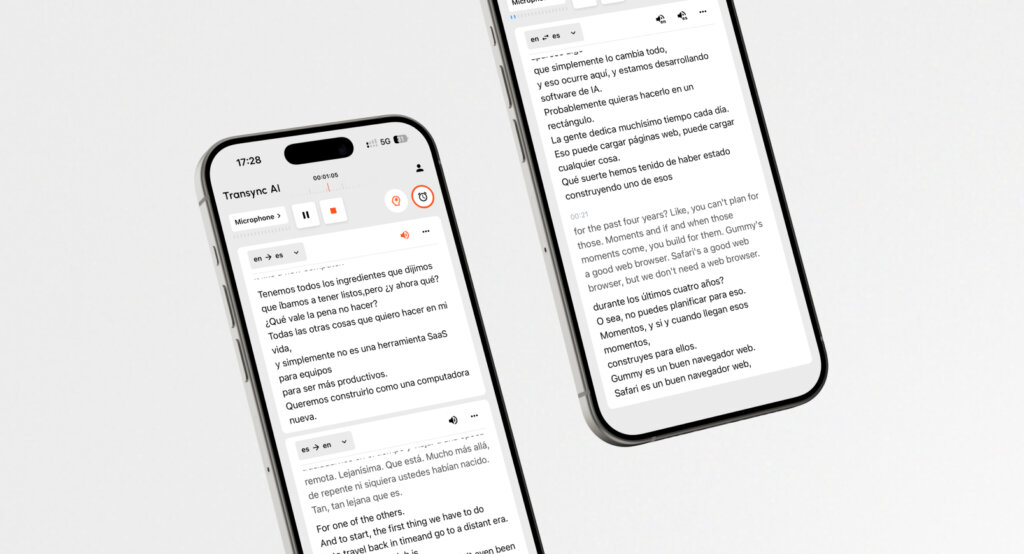
นี่คือสิ่งที่... Transync เอไอ Transync AI เป็นโมเดลประมวลผลเสียงแบบครบวงจร โดยอาศัยเทคโนโลยีการสังเคราะห์เสียงระดับสูง เพื่อมอบประสบการณ์การแปลสองภาษาแบบเคียงข้างกันโดยมีความหน่วงต่ำมาก.
ความสามารถหลักของ AI ใน Transync:
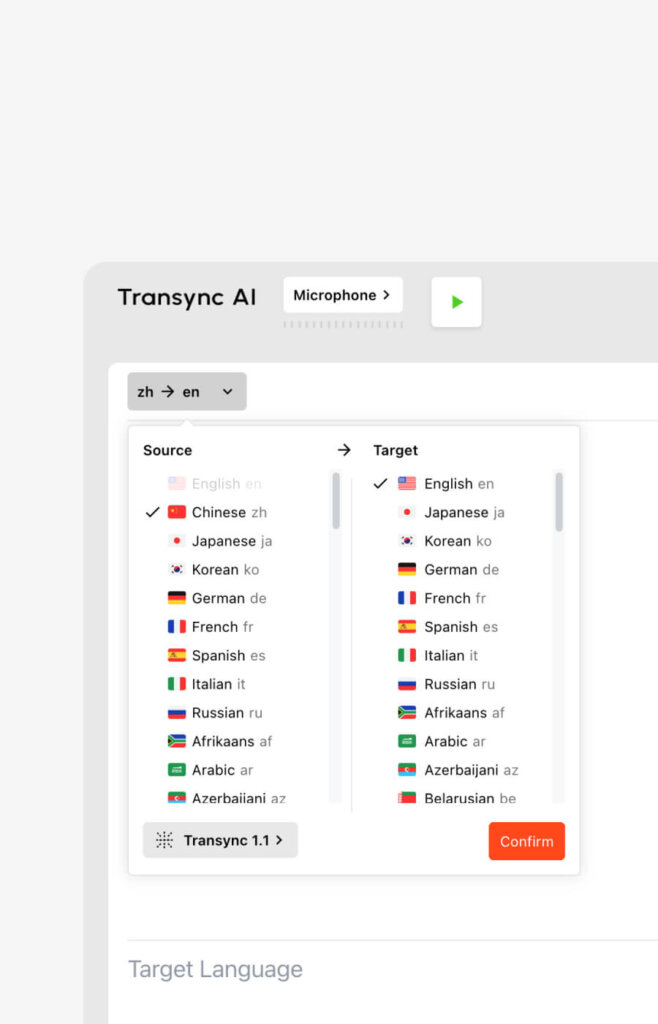
- ระบบเสียงพูดหลายภาษา: Transync AI รองรับการแปลแบบสองทิศทางใน 60 ภาษา (รวมถึงภาษาจีน อังกฤษ เยอรมัน ฝรั่งเศส และญี่ปุ่น) ไม่เพียงแต่แสดงข้อความเท่านั้น แต่ยังใช้เสียงที่ขับเคลื่อนด้วย AI เพื่อการออกอากาศที่เป็นธรรมชาติ ช่วยให้คุณได้ยินคำพูดภาษาต่างประเทศในภาษาของคุณเอง เรียนรู้เพิ่มเติมเกี่ยวกับ การแปลด้วยวาจา.
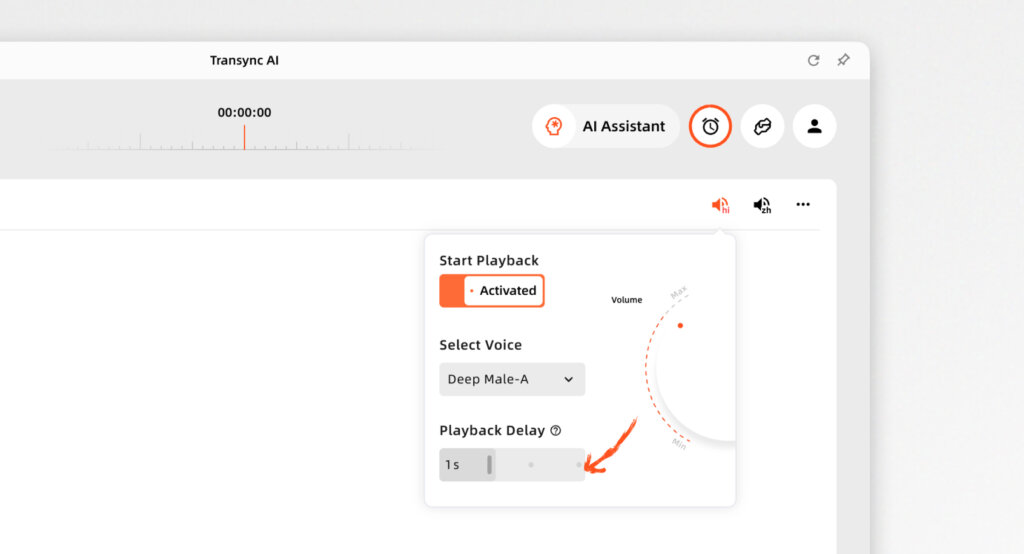
- ความหน่วงต่ำมาก: ด้วยการใช้สถาปัตยกรรมที่ได้รับการปรับให้เหมาะสม Transync AI จึงสามารถแปลข้อความแบบเรียลไทม์สำหรับการประชุมผ่าน Zoom, Teams และ Google Meet โดยไม่ต้องเสียเวลารอคอยที่น่าอึดอัด.
- ความฉลาดเชิงบริบท: ผู้ใช้สามารถกำหนดคำสำคัญ เช่น คำศัพท์เฉพาะทางอุตสาหกรรมหรือชื่อบุคคล และให้ข้อมูลพื้นฐานเพิ่มเติมได้ ซึ่งจะช่วยให้ผู้ช่วย AI ปรับการแปลให้เข้ากับน้ำเสียงและคำศัพท์ที่เหมาะสม.
5 แอปพลิเคชันที่ดีที่สุดของการสร้างเสียงด้วย AI
นอกเหนือจากผู้ช่วยเสมือนทั่วไปแล้ว นี่คือ 5 วิธีที่ดีที่สุดที่เทคโนโลยีเสียงขั้นสูงกำลังเปลี่ยนแปลงอุตสาหกรรมต่างๆ ในปัจจุบัน:
- การประชุมทางธุรกิจข้ามพรมแดน: เครื่องมืออย่าง Transync AI ใช้ระบบเสียงอัจฉริยะร่วมกับฟีเจอร์สรุปการประชุมอัตโนมัติที่ขับเคลื่อนด้วย AI ซึ่งดึงประเด็นสำคัญได้อย่างแม่นยำ ทำให้การประชุมข้ามภาษาเป็นไปอย่างมีประสิทธิภาพมากขึ้น สำหรับองค์กรขนาดใหญ่ คุณสามารถดูข้อมูลเพิ่มเติมได้ที่... แผนองค์กร.
- นักแปลรุ่นใหม่: ยุคของหุ่นยนต์แปลภาษาสำหรับการเดินทางได้ผ่านพ้นไปแล้ว ปัจจุบันเครื่องมือต่างๆ สามารถจำลองสำเนียงท้องถิ่นและจังหวะการพูดที่เป็นธรรมชาติได้อย่างราบรื่น.
- การเข้าถึงทางดิจิทัล: โปรแกรมอ่านหน้าจอและเครื่องมือช่วยสื่อสารที่ขับเคลื่อนด้วย AI แปลงข้อความเป็นเสียง ช่วยให้ผู้พิการทางสายตาได้รับประสบการณ์การฟังที่น่าพึงพอใจและไม่เหนื่อยล้ามากยิ่งขึ้น.
- บริการพากย์เสียงเนื้อหาทั่วโลก: บริษัทสื่อสามารถแปลและพากย์เสียงวิดีโอเป็นภาษาต่างๆ ได้โดยไม่ต้องจองสตูดิโออัดเสียงราคาแพง และยังคงรักษาอารมณ์ความรู้สึกของผู้พูดต้นฉบับไว้ได้.
- ระบบสนับสนุนองค์กรอัตโนมัติ: ปัจจุบันบอทบริการลูกค้าอัตโนมัติใช้เสียงที่เป็นธรรมชาติและมีความ einfühlsam ( einfühlsam หมายถึง เข้าอกเข้าใจความรู้สึกผู้อื่น) ในการแก้ไขปัญหา ทำให้ภาพลักษณ์ของแบรนด์มีความสม่ำเสมอในวงกว้าง.
บทสรุป
TTS ระบบประสาท การสังเคราะห์เสียงพูดไม่ใช่แค่แนวคิดแห่งอนาคตอีกต่อไป แต่เป็นรากฐานที่สำคัญของการสื่อสารระดับโลกในยุคปัจจุบัน การเปลี่ยนจากการใช้เสียงแบบหุ่นยนต์ที่ประกอบขึ้นจากชิ้นส่วนต่างๆ ไปสู่การเรียนรู้เชิงลึก เทคโนโลยีอย่าง Transync AI กำลังทำให้การสื่อสารข้ามภาษาเป็นไปอย่างเป็นธรรมชาติ ไม่ว่าคุณจะต้องการพัฒนาความสามารถในการแปลแบบเรียลไทม์ของทีม หรือเพียงแค่สนใจในเทคโนโลยี การทำความเข้าใจการสังเคราะห์เสียงพูดคือขั้นตอนแรกสู่อนาคตของ AI ด้านเสียง.
หากคุณต้องการประสบการณ์รุ่นถัดไป Transync เอไอ นำทางด้วยการแปลแบบเรียลไทม์ที่ขับเคลื่อนด้วย AI ซึ่งช่วยให้การสนทนาไหลลื่นอย่างเป็นธรรมชาติ คุณสามารถ ทดลองใช้ฟรี ตอนนี้.