Czy kiedykolwiek słuchałeś automatycznego głosu i zastanawiałeś się, dlaczego nie brzmi już jak niezgrabny, pozbawiony emocji robot? Sekret tej realistycznej, ludzkiej mowy tkwi w… Neuronowe TTS. Niezależnie od tego, czy korzystasz z aplikacji nawigacyjnej, słuchasz audiobooka, czy wykorzystujesz tłumacza głosowego AI podczas międzynarodowych spotkań, ta zaawansowana technologia jest siłą napędową tego doświadczenia.
W tym kompleksowym przewodniku przyjrzymy się bliżej tej technologii, jej działaniu pod powierzchnią oraz sposobom, w jakie nowoczesne platformy wykorzystują ją do natychmiastowego przełamywania barier językowych.
Czym właściwie jest neuronowa TTS?
W swojej istocie, Neuronowe TTS to zaawansowana metoda sztucznej inteligencji, która zamienia tekst pisany na naturalnie brzmiący dźwięk mowy.
W przeciwieństwie do tradycyjnych systemów syntezy mowy – które po prostu zszywały ze sobą wstępnie nagrane fragmenty audio w płaskim, mechanicznym tonie – nowoczesne podejście uczy się bezpośrednio z tysięcy godzin prawdziwej ludzkiej mowy. Wykorzystując głębokie uczenie i sztuczne sieci neuronowe, sztuczna inteligencja syntezy mowy rozumie niuanse ludzkiego języka, w tym tempo, wysokość dźwięku i kontekst emocjonalny.
Jak działa neuronowa TTS?
Aby zrozumieć, w jaki sposób generowana mowa osiąga tak realistyczną jakość, musimy przyjrzeć się trzem podstawowym etapom, przez które przechodzi system za każdym razem, gdy mówi.
1. Analiza tekstu
Najpierw system odczytuje dane wejściowe, aby ustalić Jak powiedzieć, a nie tylko jakie są słowa. Wykorzystuje przetwarzanie języka naturalnego (NLP) do normalizacji liczb, rozszerzania skrótów i rozwiązywania problemów z wymową w oparciu o kontekst. Na przykład, w zależności od zdania otaczającego, określa, czy “read” należy wymówić jako “reed” (czas teraźniejszy) czy “red” (czas przeszły).
2. Modelowanie akustyczne
Następnie model konwertuje przetworzony tekst na spektrogram mel. Można to sobie wyobrazić jako bardzo szczegółową, zwartą mapę wysokości, tonu i tempa. Na tym etapie budowany jest naturalny, ludzki aspekt głosu.
3. Vocoder
Na koniec system konwertuje mapę akustyczną na fizyczną falę dźwiękową. Zaawansowane wokodery, takie jak szeroko udokumentowany HiFi-GAN, są niezwykle wydajne i pozwalają na uzyskanie dźwięku niemal nieodróżnialnego od nagrania wykonywanego przez prawdziwego człowieka.
Architektura stojąca za nowoczesną syntezą mowy
Naukowcy opracowali kilka podejść do głębokiego uczenia, aby zasilać te systemy. Oto krótkie zestawienie dominujących architektur w tabeli porównawczej:
| Architektura | Jak generuje mowę | Przykładowe modele | Kluczowa siła | Główne ograniczenie |
| Autoregresyjny (AR) | Krok po kroku | Tacotron 2, WaveNet | Wysoka naturalność | Powolne, nie do końca “w czasie rzeczywistym” |
| Nieautoregresyjny (NAR) | Pełna sekwencja równolegle | FastSpeech, FastSpeech 2 | Do 270x szybciej | Nieco mniej ekspresyjny |
| Kompleksowo (E2E) | Tekst wejściowy, dźwięk wyjściowy – jedna sieć | VITS, NaturalSpeech | Mniej błędów, czystszy wynik | Bardziej złożone do wyszkolenia |
Rola zaawansowanego przetwarzania tekstu na mowę w tłumaczeniu w czasie rzeczywistym
Prawdziwa moc sztucznej inteligencji generującej głos ujawnia się w połączeniu z narzędziami do komunikacji na żywo. Wyobraź sobie globalne spotkanie biznesowe, na którym uczestnicy mówią różnymi językami, a Ty słyszysz wszystko od razu w swoim ojczystym języku.
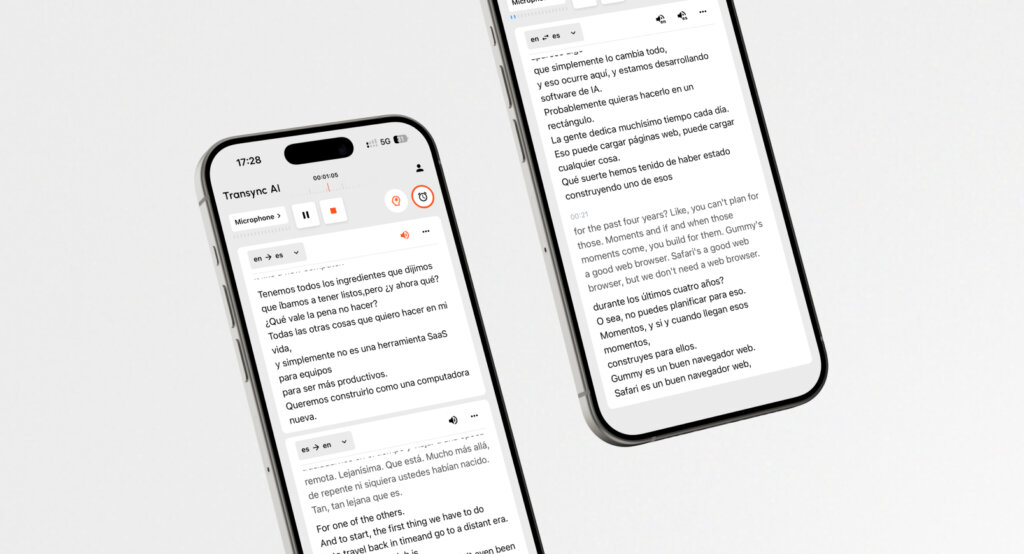
To jest dokładnie to Transync AI Osiąga. Jako kompleksowy model do przetwarzania mowy, Transync AI opiera się na syntezie głosu najwyższej klasy, aby zapewnić dwujęzyczne tłumaczenie równoległe o niemal zerowym opóźnieniu.
Kluczowe możliwości sztucznej inteligencji Transync:
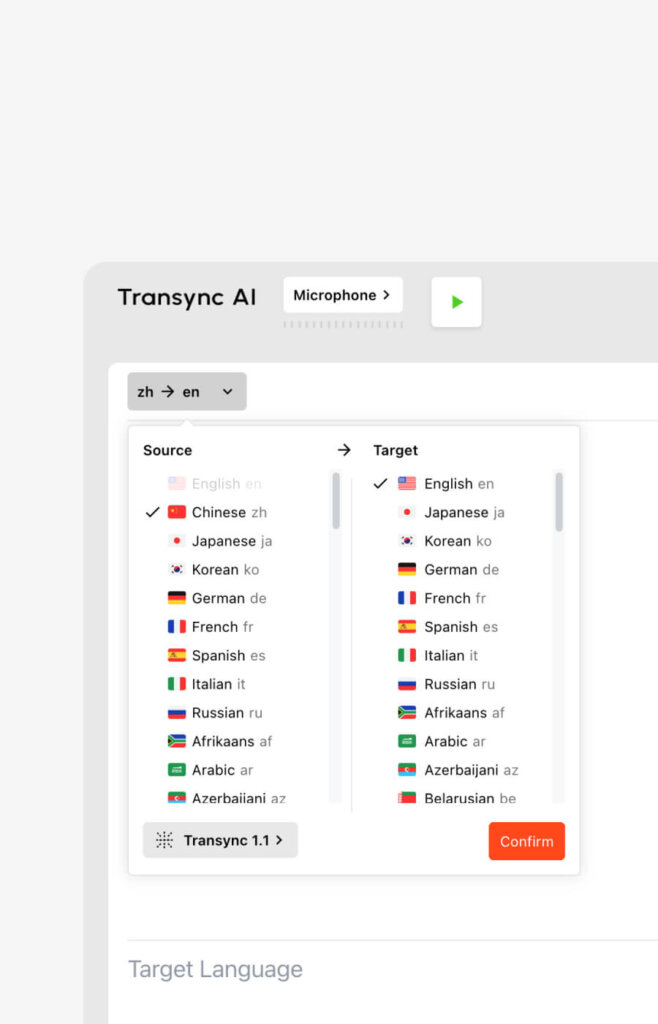
- Wyjście głosowe w wielu językach: Transync AI obsługuje tłumaczenie dwukierunkowe w 60 językach (w tym chińskim, angielskim, niemieckim, francuskim i japońskim). Nie tylko wyświetla tekst, ale także wykorzystuje głosy sterowane przez sztuczną inteligencję, zapewniając naturalne brzmienie, pozwalając usłyszeć mowę obcą w swoim języku. Dowiedz się więcej tłumaczenie ustne.
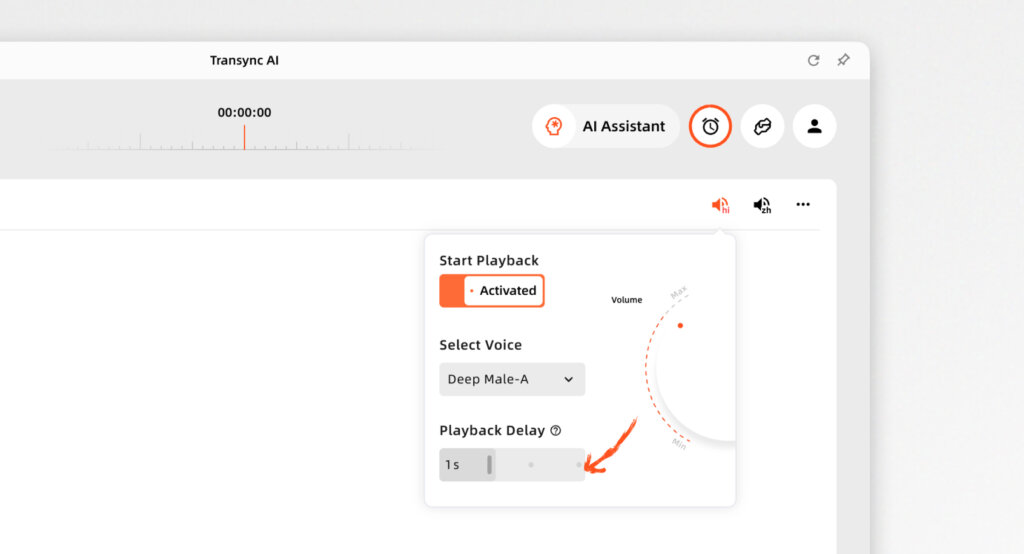
- Opóźnienie bliskie zeru: Dzięki wykorzystaniu zoptymalizowanych architektur Transync AI umożliwia tłumaczenie spotkań na żywo w platformach Zoom, Teams i Google Meet, bez uciążliwego oczekiwania.
- Inteligencja kontekstowa: Użytkownicy mogą definiować ważne słowa kluczowe, takie jak terminy branżowe czy nazwiska, i dodawać kontekst. Pomaga to asystentowi AI dostosować tłumaczenia do odpowiedniego tonu i terminologii.
5 najlepszych zastosowań generowania głosu za pomocą sztucznej inteligencji
Oprócz ogólnych asystentów wirtualnych, oto 5 najlepszych sposobów, w jakie zaawansowana technologia głosowa zmienia dzisiejsze branże:
- Spotkania biznesowe transgraniczne: Narzędzia takie jak Transync AI wykorzystują inteligentny głos w połączeniu z funkcją automatycznego podsumowania spotkania, opartą na sztucznej inteligencji, która precyzyjnie wyodrębnia kluczowe punkty, zwiększając efektywność spotkań w różnych językach. W przypadku większych organizacji można wyświetlić Plan przedsiębiorstwa.
- Tłumacze nowej generacji: Minęły czasy robotycznych tłumaczy podróżniczych. Dzisiejsze narzędzia bezproblemowo odtwarzają lokalne akcenty i naturalne rytmy.
- Dostępność cyfrowa: Czytniki ekranu i narzędzia wspomagające komunikację oparte na sztucznej inteligencji zamieniającej tekst na mowę oferują osobom z dysfunkcją wzroku o wiele przyjemniejsze i mniej męczące wrażenia słuchowe.
- Globalny dubbing treści: Firmy medialne mogą tłumaczyć i dubbingować filmy w różnych językach bez konieczności wynajmowania drogich studiów nagraniowych, zachowując przy tym emocje pierwotnego mówcy.
- Zautomatyzowane wsparcie przedsiębiorstwa: Zautomatyzowane boty obsługi klienta wykorzystują teraz empatyczne, naturalnie brzmiące głosy, aby rozwiązywać problemy, zapewniając spójny przekaz marki na dużą skalę.
Wniosek
Neuronowe TTS nie jest już tylko futurystyczną koncepcją; to aktywny fundament nowoczesnej globalnej komunikacji. Odchodząc od robotycznego, zmontowanego dźwięku i wykorzystując głębokie uczenie, technologie takie jak Transync AI sprawiają, że interakcje międzyjęzykowe stają się całkowicie naturalne. Niezależnie od tego, czy chcesz ulepszyć możliwości swojego zespołu w zakresie tłumaczeń w czasie rzeczywistym, czy po prostu interesujesz się technologią, zrozumienie syntezy mowy to pierwszy krok w przyszłość sztucznej inteligencji głosowej. Zrozumienie syntezy mowy to pierwszy krok w przyszłość sztucznej inteligencji głosowej.
Jeśli chcesz przeżyć doświadczenie nowej generacji, Transync AI wyznacza trendy dzięki tłumaczeniom w czasie rzeczywistym, opartym na sztucznej inteligencji, które zapewniają naturalny przepływ rozmów. Możesz wypróbuj za darmo Teraz.