Bạn đã bao giờ nghe một giọng nói tự động và tự hỏi tại sao nó không còn nghe giống như một con robot vụng về, vô cảm nữa chưa? Bí mật đằng sau giọng nói chân thực, giống con người này là gì? Dịch thuật chuyển văn bản thành giọng nói thần kinh. Cho dù bạn đang sử dụng ứng dụng điều hướng, nghe sách nói hay dùng trình dịch giọng nói AI cho các cuộc họp toàn cầu, công nghệ tiên tiến này chính là động lực thúc đẩy trải nghiệm.
Trong hướng dẫn toàn diện này, chúng ta sẽ tìm hiểu công nghệ này là gì, cách thức hoạt động của nó bên trong và cách các nền tảng hiện đại tận dụng nó để phá vỡ rào cản ngôn ngữ ngay lập tức.
Công nghệ chuyển văn bản thành giọng nói dựa trên thần kinh (Neural TTS) chính xác là gì?
Về bản chất, Dịch thuật chuyển văn bản thành giọng nói thần kinh Đây là một phương pháp trí tuệ nhân tạo tiên tiến giúp chuyển đổi văn bản thành âm thanh nói tự nhiên.
Không giống như các hệ thống chuyển văn bản thành giọng nói truyền thống—vốn chỉ đơn giản là ghép nối các đoạn âm thanh đã được ghi âm sẵn với giọng điệu đều đều và máy móc—phương pháp hiện đại học hỏi trực tiếp từ hàng nghìn giờ giọng nói thực của con người. Bằng cách sử dụng học sâu và mạng nơ-ron nhân tạo, trí tuệ nhân tạo chuyển văn bản thành giọng nói hiểu được những sắc thái tinh tế của ngôn ngữ con người, bao gồm nhịp điệu, cao độ và ngữ cảnh cảm xúc.
Công nghệ chuyển văn bản thành giọng nói dựa trên thần kinh hoạt động như thế nào?
Để hiểu được cách tạo giọng nói đạt được chất lượng sống động như thật, chúng ta cần xem xét ba giai đoạn chính mà hệ thống trải qua mỗi khi phát ra âm thanh.
1. Phân tích văn bản
Đầu tiên, hệ thống đọc dữ liệu đầu vào để tìm ra Làm sao Nó không chỉ diễn đạt bằng lời mà còn bằng chính từ ngữ. Nó sử dụng Xử lý Ngôn ngữ Tự nhiên (NLP) để chuẩn hóa số, mở rộng các từ viết tắt và giải quyết các cách phát âm khó dựa trên ngữ cảnh. Ví dụ, nó xác định xem nên phát âm “read” là “reed” (thì hiện tại) hay “red” (thì quá khứ) tùy thuộc vào câu xung quanh.
2. Mô hình hóa âm thanh
Tiếp theo, mô hình chuyển đổi văn bản đã xử lý thành phổ Mel. Bạn có thể coi đây như một bản đồ chi tiết, cô đọng về cao độ, âm sắc và nhịp điệu. Giai đoạn này chính là nơi mà khía cạnh tự nhiên, giống con người của giọng nói được xây dựng.
3. Bộ mã hóa giọng nói (Vocoder)
Cuối cùng, hệ thống chuyển đổi bản đồ âm thanh đó thành dạng sóng âm thanh vật lý. Các bộ mã hóa giọng nói tiên tiến, chẳng hạn như bộ mã hóa được ghi nhận rộng rãi, đã được sử dụng rộng rãi. HiFi-GAN, Chúng có khả năng tạo ra âm thanh đầu ra gần như không thể phân biệt được với bản ghi âm giọng nói thật của con người.
Kiến trúc đằng sau công nghệ tổng hợp giọng nói hiện đại
Các nhà nghiên cứu đã phát triển một số phương pháp học sâu để vận hành các hệ thống này. Dưới đây là bảng so sánh tóm tắt các kiến trúc chủ đạo:
| Ngành kiến trúc | Cách thức tạo ra lời nói | Ví dụ về các mô hình | Điểm mạnh chính | Hạn chế chính |
| Tự hồi quy (AR) | Từng bước một | Tacotron 2, WaveNet | Độ tự nhiên cao | Chậm, không thực sự "thời gian thực"“ |
| Không tự hồi quy (NAR) | Trình tự đầy đủ song song | FastSpeech, FastSpeech 2 | Nhanh hơn tới 270 lần | Ít biểu cảm hơn một chút |
| Từ đầu đến cuối (E2E) | Đầu vào văn bản, đầu ra âm thanh – một mạng lưới duy nhất. | VITS, NaturalSpeech | Ít lỗi hơn, kết quả đầu ra sạch hơn | Việc đào tạo phức tạp hơn |
Vai trò của công nghệ chuyển văn bản thành giọng nói tiên tiến trong dịch thuật thời gian thực
Sức mạnh thực sự của công nghệ tạo giọng nói bằng AI tỏa sáng khi được kết hợp với các công cụ giao tiếp trực tiếp. Hãy tưởng tượng bạn tham dự một cuộc họp kinh doanh toàn cầu với nhiều người tham gia nói các ngôn ngữ khác nhau, nhưng bạn có thể nghe mọi thứ ngay lập tức bằng tiếng mẹ đẻ của mình.
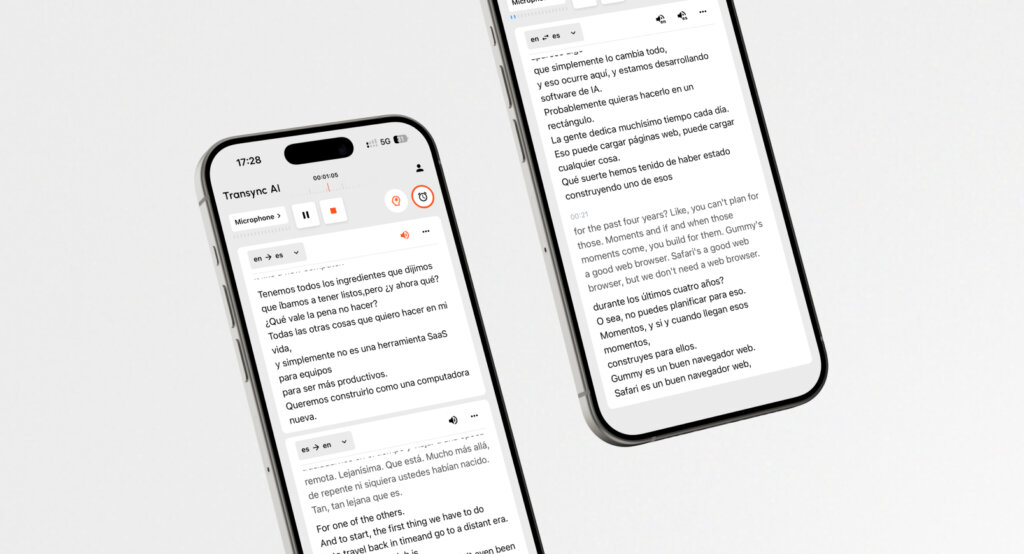
Đây chính xác là điều AI đồng bộ hoàn thành xuất sắc. Là một mô hình xử lý giọng nói toàn diện, Transync AI dựa vào công nghệ tổng hợp giọng nói hàng đầu để mang đến trải nghiệm dịch song ngữ song song với độ trễ gần như bằng không.
Các khả năng chính của Transync AI:
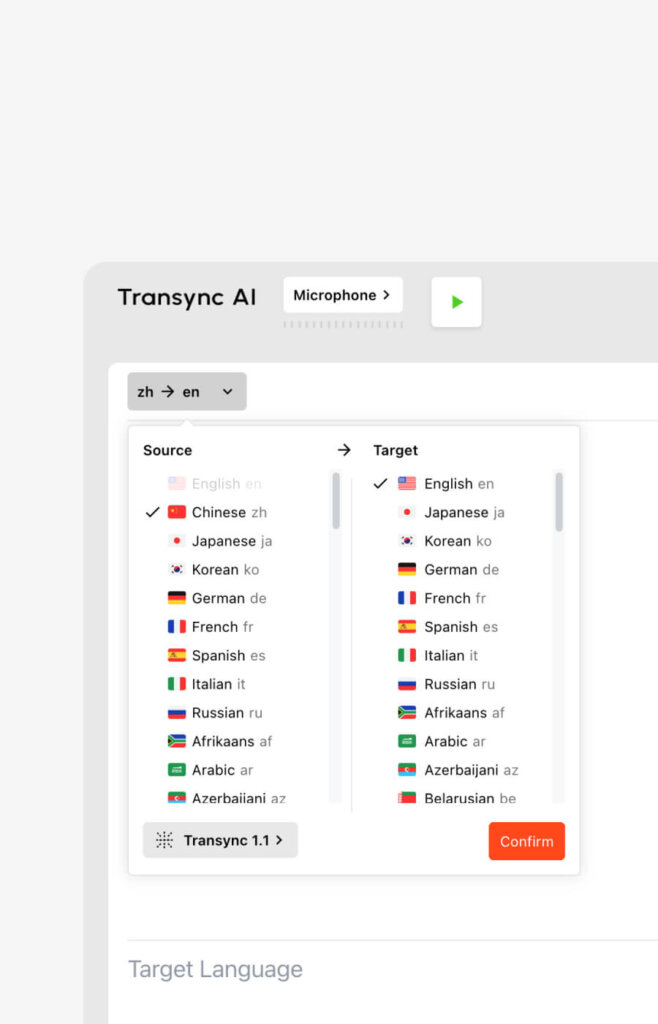
- Phát âm đa ngôn ngữ: Transync AI hỗ trợ dịch thuật hai chiều 60 ngôn ngữ (bao gồm tiếng Trung, tiếng Anh, tiếng Đức, tiếng Pháp và tiếng Nhật). Ứng dụng không chỉ hiển thị văn bản mà còn sử dụng giọng nói do AI điều khiển để phát sóng tự nhiên, cho phép bạn nghe tiếng nước ngoài bằng ngôn ngữ mẹ đẻ. Tìm hiểu thêm về Transync AI. bản dịch bằng lời nói.
- Độ trễ gần bằng không: Bằng cách sử dụng kiến trúc được tối ưu hóa, Transync AI cung cấp dịch thuật trực tiếp các cuộc họp trên Zoom, Teams và Google Meet mà không cần phải chờ đợi lâu gây khó chịu.
- Trí tuệ theo ngữ cảnh: Người dùng có thể xác định các từ khóa quan trọng như thuật ngữ chuyên ngành hoặc tên cá nhân, và cung cấp bối cảnh cụ thể. Điều này giúp trợ lý AI điều chỉnh bản dịch sao cho phù hợp với giọng điệu và thuật ngữ.
5 ứng dụng tốt nhất của công nghệ tạo giọng nói bằng AI
Ngoài các trợ lý ảo thông thường, đây là 5 cách tốt nhất mà công nghệ giọng nói tiên tiến đang làm thay đổi các ngành công nghiệp hiện nay:
- Các cuộc gặp gỡ kinh doanh xuyên biên giới: Các công cụ như Transync AI sử dụng công nghệ nhận dạng giọng nói thông minh kết hợp với tính năng tóm tắt cuộc họp tự động được hỗ trợ bởi trí tuệ nhân tạo, giúp trích xuất chính xác các điểm chính, làm cho các cuộc họp đa ngôn ngữ hiệu quả hơn. Đối với các tổ chức lớn hơn, bạn có thể xem... Kế hoạch doanh nghiệp.
- Những người dịch thế hệ tiếp theo: Thời đại của những người phiên dịch du lịch tự động đã qua rồi. Các công cụ hiện đại tái tạo giọng địa phương và ngữ điệu tự nhiên một cách hoàn hảo.
- Khả năng tiếp cận kỹ thuật số: Các phần mềm đọc màn hình và công cụ hỗ trợ giao tiếp được hỗ trợ bởi trí tuệ nhân tạo chuyển văn bản thành giọng nói mang đến cho người dùng khiếm thị trải nghiệm nghe dễ chịu hơn và ít mệt mỏi hơn.
- Lồng tiếng nội dung toàn cầu: Các công ty truyền thông có thể dịch và lồng tiếng video sang nhiều ngôn ngữ khác nhau mà không cần thuê các phòng thu âm đắt tiền, vẫn giữ được cảm xúc của người nói gốc.
- Hỗ trợ doanh nghiệp tự động: Các chatbot chăm sóc khách hàng tự động hiện nay sử dụng giọng nói tự nhiên, giàu cảm xúc để giải quyết vấn đề, mang đến một giọng điệu thương hiệu nhất quán trên quy mô lớn.
Phần kết luận
Dịch thuật chuyển văn bản thành giọng nói thần kinh Công nghệ nhận dạng giọng nói không còn chỉ là một khái niệm viễn tưởng; nó đã trở thành nền tảng thiết thực của giao tiếp toàn cầu hiện đại. Bằng cách loại bỏ âm thanh được ghép nối một cách máy móc và áp dụng học sâu, các công nghệ như Transync AI đang làm cho các tương tác đa ngôn ngữ trở nên hoàn toàn tự nhiên. Cho dù bạn đang muốn cải thiện khả năng dịch thuật thời gian thực của nhóm mình hay chỉ đơn giản là tò mò về công nghệ này, việc hiểu về tổng hợp giọng nói là bước đầu tiên hướng tới tương lai của trí tuệ nhân tạo giọng nói.
Nếu bạn muốn có trải nghiệm thế hệ tiếp theo, AI đồng bộ dẫn đầu với tính năng dịch thuật thời gian thực, hỗ trợ bởi AI giúp cuộc trò chuyện diễn ra tự nhiên. Bạn có thể dùng thử miễn phí Hiện nay.