Haben Sie sich jemals gefragt, warum eine Computerstimme nicht mehr wie ein unbeholfener, emotionsloser Roboter klingt? Das Geheimnis hinter dieser realistischen, menschenähnlichen Sprache ist Neurales TTS. Ob Sie eine Navigations-App nutzen, ein Hörbuch hören oder einen KI-Sprachübersetzer für internationale Meetings verwenden – diese fortschrittliche Technologie ist der Motor für dieses Erlebnis.
In diesem umfassenden Leitfaden werden wir untersuchen, was diese Technologie ist, wie sie im Detail funktioniert und wie moderne Plattformen sie nutzen, um Sprachbarrieren im Handumdrehen abzubauen.
Was genau ist neuronales TTS?
Im Kern, Neurales TTS ist eine hochentwickelte KI-Methode, die geschriebenen Text in natürlich klingenden gesprochenen Ton umwandelt.
Anders als herkömmliche Text-to-Speech-Systeme, die lediglich vorab aufgenommene Audiofragmente in einem monotonen, mechanischen Tonfall zusammenfügten, lernt der moderne Ansatz direkt aus Tausenden von Stunden echter menschlicher Sprache. Durch den Einsatz von Deep Learning und künstlichen neuronalen Netzen versteht die Text-to-Speech-KI die Nuancen der menschlichen Sprache, darunter Sprechtempo, Tonhöhe und emotionalen Kontext.
Wie funktioniert neuronales TTS?
Um zu verstehen, wie die Spracherzeugung eine so lebensechte Qualität erreicht, müssen wir uns die drei Hauptphasen ansehen, die ein System jedes Mal durchläuft, wenn es spricht.
1. Textanalyse
Zuerst liest das System die Eingabe, um herauszufinden Wie Es geht nicht nur um die einzelnen Wörter, sondern auch um deren Bedeutung. Mithilfe von Natural Language Processing (NLP) werden Zahlen normalisiert, Abkürzungen aufgelöst und schwierige Aussprachen kontextbezogen korrigiert. Beispielsweise wird je nach Kontext entschieden, ob “read” als “reed” (Präsens) oder “red” (Präteritum) ausgesprochen wird.
2. Akustische Modellierung
Anschließend wandelt das Modell den verarbeiteten Text in ein Mel-Spektrogramm um. Man kann sich das als eine hochdetaillierte, kompakte Karte von Tonhöhe, Klangfarbe und Timing vorstellen. In dieser Phase entsteht der natürliche, menschenähnliche Charakter der Stimme.
3. Der Vocoder
Schließlich wandelt das System diese akustische Karte in eine physikalische Audiowellenform um. Fortschrittliche Vocoder, wie beispielsweise der vielfach dokumentierte HiFi-GAN, Sie sind unglaublich leistungsstark darin, ein Ergebnis zu erzeugen, das von einer echten menschlichen Aufnahme kaum zu unterscheiden ist.
Die Architekturen hinter der modernen Sprachsynthese
Forscher haben verschiedene Deep-Learning-Ansätze entwickelt, um diese Systeme zu betreiben. Hier ist eine kurze Übersicht der wichtigsten Architekturen in einer Vergleichstabelle:
| Architektur | Wie es Sprache erzeugt | Beispielmodelle | Hauptstärke | Hauptbeschränkung |
| Autoregressiv (AR) | Schritt für Schritt | Tacotron 2, WaveNet | Hohe Natürlichkeit | Langsam, nicht wirklich “Echtzeit”.” |
| Nicht-autoregressiv (NAR) | Vollständige Sequenz parallel | FastSpeech, FastSpeech 2 | Bis zu 270-mal schneller | Etwas weniger ausdrucksstark |
| End-to-End (E2E) | Text rein, Audio raus – ein Netzwerk | VITS, Natürliche Sprache | Weniger Fehler, sauberere Ausgabe | Komplexer zu trainieren |
Die Rolle fortschrittlicher Text-zu-Sprache-Technologien bei der Echtzeitübersetzung
Die wahre Stärke der KI-Sprachgenerierung zeigt sich in Kombination mit Live-Kommunikationstools. Stellen Sie sich vor, Sie nehmen an einem internationalen Geschäftstreffen teil, bei dem die Teilnehmer verschiedene Sprachen sprechen, aber Sie hören alles sofort in Ihrer Muttersprache.
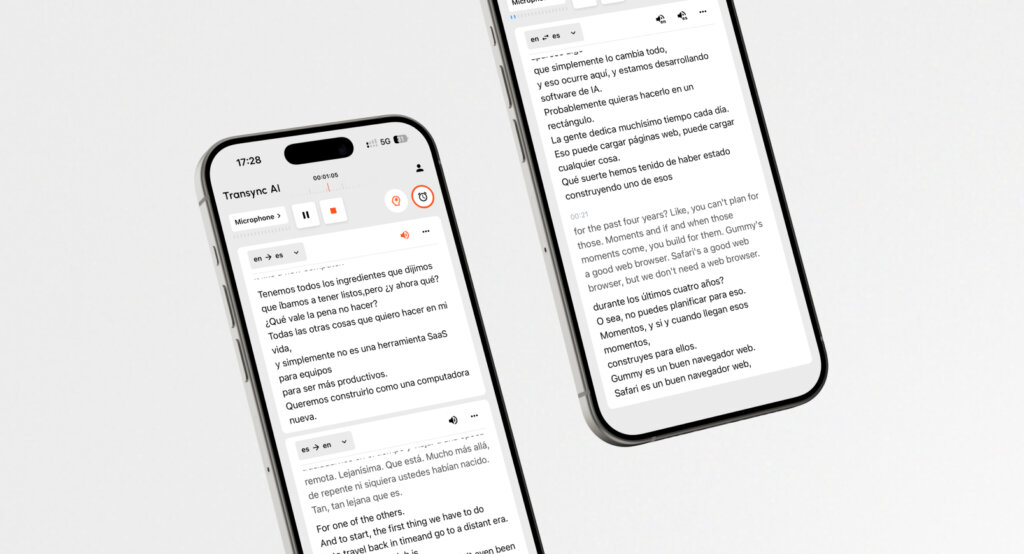
Genau das ist es. Transync AI Transync AI erreicht dies. Als umfassendes Sprachverarbeitungsmodell nutzt es erstklassige Sprachsynthese, um ein nahezu latenzfreies, zweisprachiges Side-by-Side-Übersetzungserlebnis zu bieten.
Wichtigste KI-Funktionen von Transync:
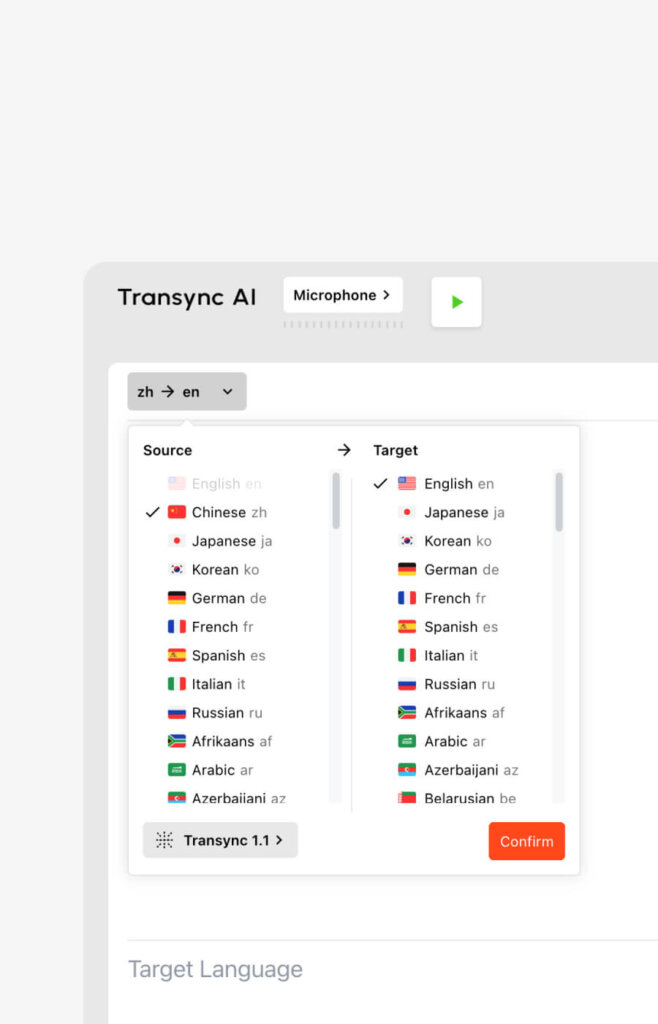
- Mehrsprachige Sprachausgabe: Transync AI unterstützt bidirektionale Übersetzung in 60 Sprachen (darunter Chinesisch, Englisch, Deutsch, Französisch und Japanisch). Es zeigt nicht nur Text an, sondern nutzt KI-gesteuerte Stimmen für eine natürliche Wiedergabe, sodass Sie fremdsprachige Inhalte in Ihrer Sprache hören können. Erfahren Sie mehr über verbale Übersetzung.
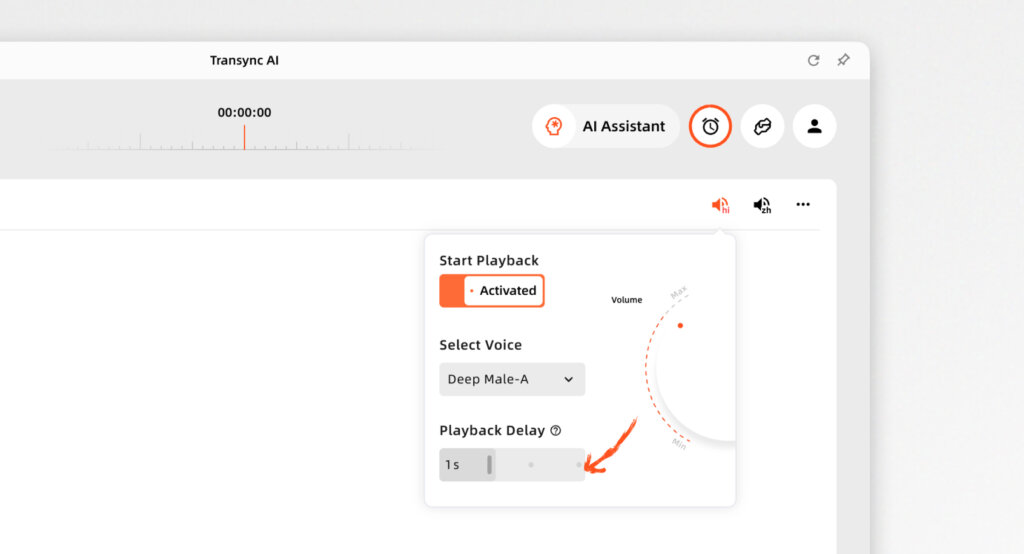
- Nahezu latenzfrei: Durch die Nutzung optimierter Architekturen bietet Transync AI Live-Meeting-Übersetzung für Zoom, Teams und Google Meet ohne lästige Wartezeiten.
- Kontextuelle Intelligenz: Nutzer können wichtige Schlüsselwörter wie Branchenbegriffe oder Personennamen definieren und Kontextinformationen bereitstellen. Dies hilft dem KI-Assistenten, Übersetzungen an den richtigen Ton und die passende Terminologie anzupassen.
Die 5 besten Anwendungsfälle für KI-Sprachgenerierung
Abgesehen von allgemeinen virtuellen Assistenten, hier die 5 besten Wege, wie fortschrittliche Sprachtechnologie heute Branchen verändert:
- Grenzüberschreitende Geschäftstreffen: Tools wie Transync AI nutzen intelligente Sprachausgabe in Kombination mit einer KI-gestützten automatischen Besprechungszusammenfassung, die die wichtigsten Punkte präzise extrahiert und so sprachübergreifende Besprechungen effizienter gestaltet. Für größere Organisationen können Sie die Unternehmensplan.
- Übersetzer der nächsten Generation: Die Zeiten roboterhafter Reiseübersetzer sind vorbei. Heutige Tools ahmen lokale Akzente und natürliche Sprachmelodien nahtlos nach.
- Digitale Barrierefreiheit: Bildschirmleseprogramme und unterstützende Kommunikationshilfen, die auf KI-gestützter Text-zu-Sprache-Technologie basieren, bieten sehbehinderten Nutzern ein deutlich angenehmeres und weniger ermüdendes Hörerlebnis.
- Globale Inhaltssynchronisation: Medienunternehmen können Videos in verschiedene Sprachen übersetzen und synchronisieren, ohne teure Tonstudios buchen zu müssen, und dabei die Emotionen des ursprünglichen Sprechers beibehalten.
- Automatisierter Unternehmenssupport: Automatisierte Kundenservice-Bots nutzen heute empathische, natürlich klingende Stimmen, um Probleme zu lösen und so eine einheitliche Markenstimme in großem Umfang zu gewährleisten.
Abschluss
Neurales TTS Sprachsynthese ist längst keine Zukunftsvision mehr, sondern die Grundlage moderner globaler Kommunikation. Durch den Verzicht auf roboterhafte, zusammengestückelte Audioaufnahmen und die Nutzung von Deep Learning ermöglichen Technologien wie Transync AI völlig natürliche, sprachübergreifende Interaktionen. Ob Sie die Echtzeit-Übersetzungsfähigkeiten Ihres Teams verbessern oder einfach nur neugierig auf die Technologie sind: Das Verständnis von Sprachsynthese ist der erste Schritt in die Zukunft der Sprach-KI.
Wenn Sie ein Erlebnis der nächsten Generation wünschen, Transync AI ist führend mit Echtzeit-Übersetzungen auf KI-Basis, die einen natürlichen Gesprächsfluss gewährleisten. Sie können kostenlos testen Jetzt.